阅读本文大概需要 5 分钟。
来自: juejin.cn/post/7284158980113350691
推荐一个我自己写的程序员常用工具网站:
http://cxytools.com
涵盖了时间戳、JSON工具、随机数、UUID、文本对比等常用工具,复制URL 可直达。
以下是正文。
我们知道提交任务到线程池有两种方法,一种是execute,一种是submit
❝
这两种提交方式占用的内存是一样大的吗?一个空任务究竟占多少内存?
❞
通过源码分析一下
public static void main(String[] args) {
ThreadPoolExecutor threadPoolExecutor =
new ThreadPoolExecutor(8, 8, 15, TimeUnit.MINUTES, new LinkedBlockingQueue<>(), new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 0; i < (int) 2e5; i++) {
int finalI = i;
threadPoolExecutor.execute(() -> {
// 乱写...
int p = finalI;
LockSupport.park();
});
}
LockSupport.park();
}这是一段典型的使用execute往线程池中提交任务的代码,这里是提交了20w个任务
execute的源码如下:
// ThreadPoolExecutor.execute
public void execute(Runnable command) {
// 判空
if (command == null)
throw new NullPointerException();
int c = ctl.get();
// 当前线程数没达到核心线程数
if (workerCountOf(c) < corePoolSize) {
// 创建核心线程
if (addWorker(command, true))
return;
c = ctl.get();
}
// 尝试往阻塞队列中提交任务
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 二次检查,防止进入execute之后,线程池shutdown了
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 阻塞队列放不下,创建非核心线程
else if (!addWorker(command, false))
reject(command);
}execute体现的就是线程池的工作原理, addWorker 中有更复杂的逻辑来保证worker的原子性地插入,这个逻辑以后有机会可以聊聊
那么使用execute提交一个任务,这个任务究竟多大呢?
我们使用得最多的就是使用 lambda表达式 来提交任务
threadPoolExecutor.execute(() -> {
// ...
});那么这个lambda实例占用多少个字节呢?
16字节;在开了指针压缩的情况下,对象头占12个字节,4个字节用于填充补齐到8的整数倍,由于这个lambda实例中没有其他成员变量了,所以它就是占据16个字节
除此之外,如果使用的是 LinkedBlockingQueue 阻塞队列来存放任务,那么还涉及到 LinkedBlockingQueue 中的 Node , LinkedBlockingQueue 会使用这个Node来封装任务
static class Node<E> {
E item;
/**
* One of:
* - the real successor Node
* - this Node, meaning the successor is head.next
* - null, meaning there is no successor (this is the last node)
*/
Node<E> next;
Node(E x) { item = x; }
}这个Node占多少字节呢?
24个字节;同样对象头占12字节,item是一个4字节的引用,next也是一个4字节的引用,一共20字节,4个字节用于填充对齐,所以一个node对象是24字节
所以在使用execute且阻塞队列是 LinkedBlockingQueue 时一个任务占用40个字节
如果execute 20w个任务,会占用800w个字节,约7.6MB内存
堆快照如下:
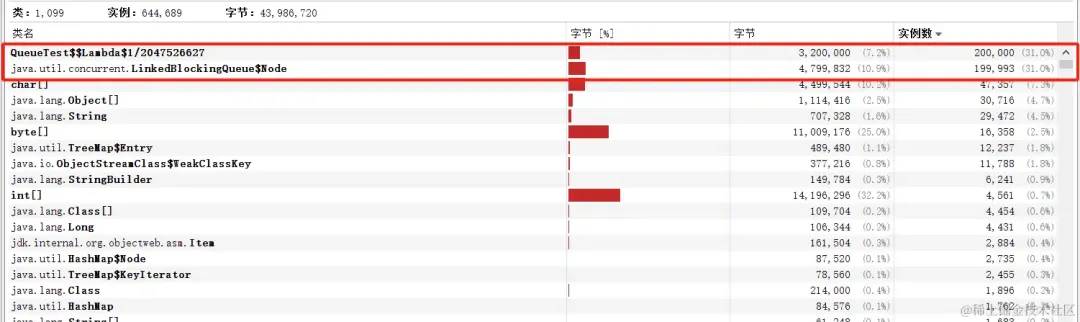
图片
如果是使用 ArrayBlockingQueue 的话,只有lambda实例这一个开销,所以只会使用320w个字节,约3.05MB内存,比起 LinkedBlockingQueue 少了一倍不止
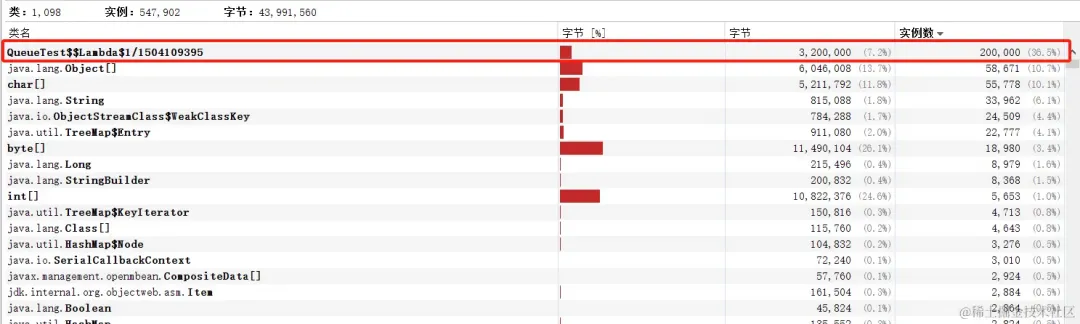
图片
接下来分析一下submit
// AbstractExecutorService.submit
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}submit中调用了 newTaskFor 方法来返回一个ftask对象,然后execute这个ftask对象, newTaskFor 代码如下:
// AbstractExecutorService.newTaskFor
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}newTaskFor 又调用我们熟悉的 FutureTask 的有参构造器来创建一个 futureTask 实例,代码如下:
// FutureTask有参构造器
public FutureTask(Runnable runnable, V result) {
this.callable = Executors.callable(runnable, result);
this.state = NEW; // ensure visibility of callable
}这个有参构造器中又调用了 Executors 的静态方法callable创建一个callable实例来赋值给 futureTask 的callable属性,代码如下:
// Executors.callable
public static <T> Callable<T> callable(Runnable task, T result) {
if (task == null)
throw new NullPointerException();
return new RunnableAdapter<T>(task, result);
}最后还是使用了 RunnableAdapter 来包装这个task,代码如下:
// Executors.RunnableAdapter类
static final class RunnableAdapter<T> implements Callable<T> {
final Runnable task;
final T result;
RunnableAdapter(Runnable task, T result) {
this.task = task;
this.result = result;
}
public T call() {
task.run();
return result;
}
}梳理一下整个流程,run和call的关系的伪代码如下
// submit
run(){
// RunnableAdapter.call
call(){
// task.run
run(){
// 实际的任务
}
}
}为什么要这么麻烦封装一层又一层呢?
可能是为了适配。submit的返回值是 futureTask ,但是我们传给submit的是个runnable,然后submit会把这个runnable继续传给 futureTask , futureTask 的结果值是null,但是又由于 futureTask 的run方法已经被重写成执行call方法了,所以只能在call方法里面跑我们真正的run方法了
所以最后用了submit方法之后,会多出两类对象,一个是 FutureTask ,一个是 RunnableAdapter
FutureTask 的成员变量如下:
/** The underlying callable; nulled out after running */
private Callable<V> callable;
/** The result to return or exception to throw from get() */
private Object outcome; // non-volatile, protected by state reads/writes
/** The thread running the callable; CASed during run() */
private volatile Thread runner;
/** Treiber stack of waiting threads */
private volatile WaitNode waiters;一个 FutureTask 对象占用的字节数是12+4+4+4+4=28个字节,还需要4个字节做填充,所以一共是32个字节
RunnableTask 的成员变量如下:
final Runnable task; final T result;一个 RunnableTask 对象占用的字节数是12+4+4=20个字节,同样需要4个字节做填充,所以一共是24个字节
所以在使用submit且阻塞队列是 LinkedBlockingQueue 时一个任务占用96个字节
如果submit 20w个任务,会占用1920w个字节,约18.31MB内存
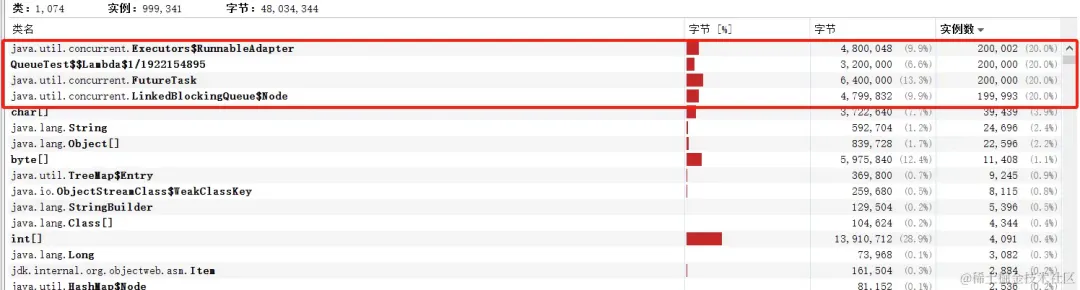
图片
如果使用的是 ArrayBlockingQueue 会省去Node的占用的内存
public static void main(String[] args) {
ThreadPoolExecutor threadPoolExecutor =
new ThreadPoolExecutor(8, 8, 15, TimeUnit.MINUTES, new LinkedBlockingQueue<>(), new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 0; i < (int) 2e5; i++) {
// int finalI = i;
threadPoolExecutor.submit(() -> {
// 乱写...
// int p = finalI;
LockSupport.park();
});
}
LockSupport.park();
}如果在lambda中没有使用到上下文的其他变量时,是不会重复创建lambda实例的,只会创建一个
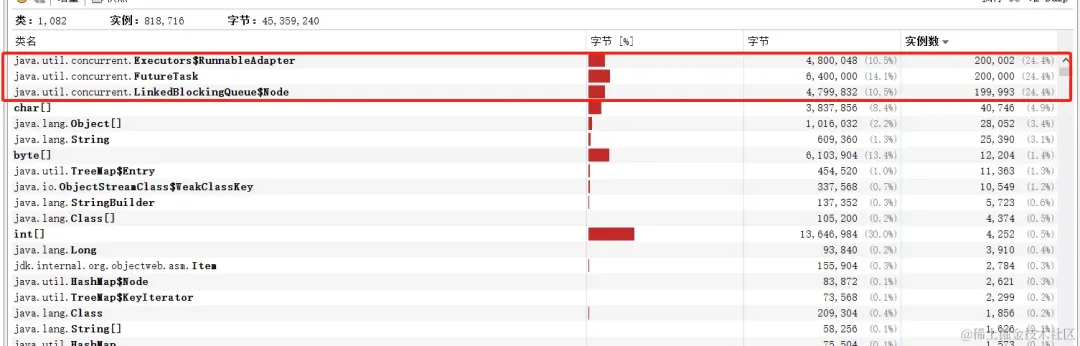
图片
只会创建一个lambda实例
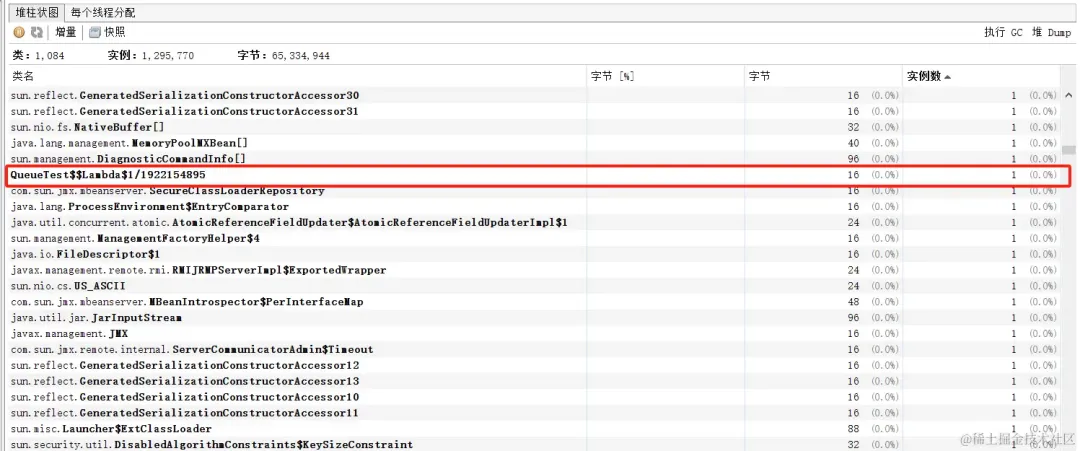
图片
如果配合上 ArrayBlockingQueue 以及execute,提交20w个任务的空间复杂度可以降至 O(1)
因为20w个任务的实例都是同一个
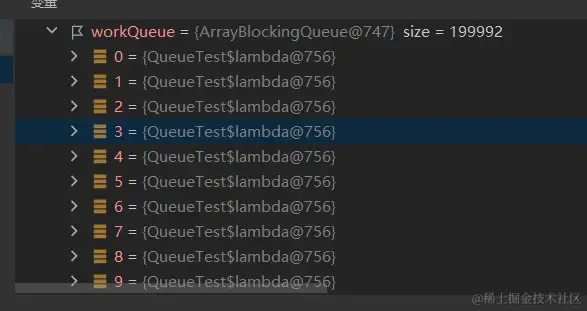
图片
如果是lambda中没有上下文变量,使用的队列是 ArrayBlockingQueue ,提交方式是execute,那么空间复杂度可以达到O(1);如果lambda中有上下文变量,每次提交任务都会创建一个新的lambda实例;
如果使用的队列是 LinkedBlockingQueue ,那么还要算上 LinkedBlockingQueue 的Node实例的开销;如果提交的方式是submit,那么还要算上 FutureTask 和 RunnableAdapter 的开销
当然这里只是浅层地讨论了一下创建一个空任务所占用的内存大小,如果是更加复杂的任务,任务内的内存开销需要算上
如果错误,请斧正。
文章收集整理于网络,请勿商用,仅供个人学习使用,如有侵权,请联系作者删除,如若转载,请注明出处:http://www.cxyroad.com/16065.html
